SiteCrawler is a website downloading application that lets you capture entire sites or selected portions, like image galleries. It features powerful settings that no other application offers.
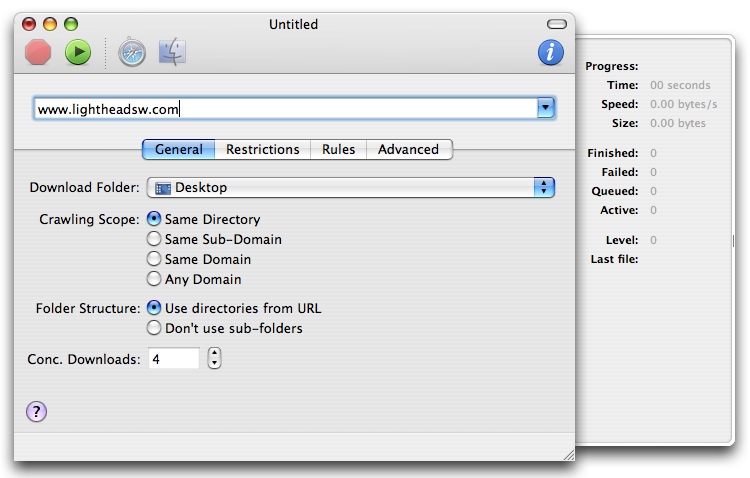 You don't have to be an expert to use SiteCrawler. While the advanced features are easily accessible, they don't bog down the basic settings, so you can stay focused on the task at hand. To start crawling a site, enter a web address and choose a destination folder on your disk. Further options help you fine-tune the behavior, such as which parts of the site to access.
You don't have to be an expert to use SiteCrawler. While the advanced features are easily accessible, they don't bog down the basic settings, so you can stay focused on the task at hand. To start crawling a site, enter a web address and choose a destination folder on your disk. Further options help you fine-tune the behavior, such as which parts of the site to access.
While SiteCrawler crawls a site, you can pause it to change the settings. When you resume, the new settings are picked up immediately. So if you see files being downloaded that you don't really want, there's no need to stop the session.
You can save sessions for later, even in the midst of downloading. You can then re-open the session later, and pick up right where you left off!

SiteCrawler is currently available in English and Swedish. More languages will be supported in the future. *
Normally, you choose a single web address to start from. But using URL patterns, you can choose several. To start from a numeric range, put the range inside a pair of square brackets. If you instead have a list of a few options, put those inside a pair of curly brackets. You can combine these pattern types to create even more advanced URLs. SiteCrawler 1.1 has even more powerful URL patterns that lets you use square brackets inside curly ones! An address using URL patterns might look like this:
http://example.com/{stuff,images}/img[100-150].jpg
By default, SiteCrawler changes references in downloaded HTML pages to point locally. This means you can browse downloaded sites without problems with broken links and links that point to the originating web site. Also, the file extensions of downloaded files are changed to match their actual content.
The SiteCrawler engine is optimized for high-speed Internet connections and takes advantage of modern web server technologies to speed up downloads. In addition to regular HTTP, SiteCrawler also supports secure connections (HTTPS).
 Version 1.1 adds full AppleScript support, so you can more easily integrate SiteCrawler with many other applications. You can control all aspects of a session, including rules.
Version 1.1 adds full AppleScript support, so you can more easily integrate SiteCrawler with many other applications. You can control all aspects of a session, including rules.
 SiteCrawler is built as a universal binary, which means it runs natively on both PowerPC and Intel Macs.
SiteCrawler is built as a universal binary, which means it runs natively on both PowerPC and Intel Macs.
SiteCrawler handles authentication with ease, no matter whether the web site requires you to log in using HTTP authentication or with a login form. If it's the latter, you can use SiteCrawler's Safari integration - simply log in using Safari, and SiteCrawler will automatically inherit the session.
When a web site requires you to log in using HTTP authentication (when a log in sheet drops down in Safari), SiteCrawler asks you for the log in information. And if the password is already in your keychain, you'll get the option to use that.
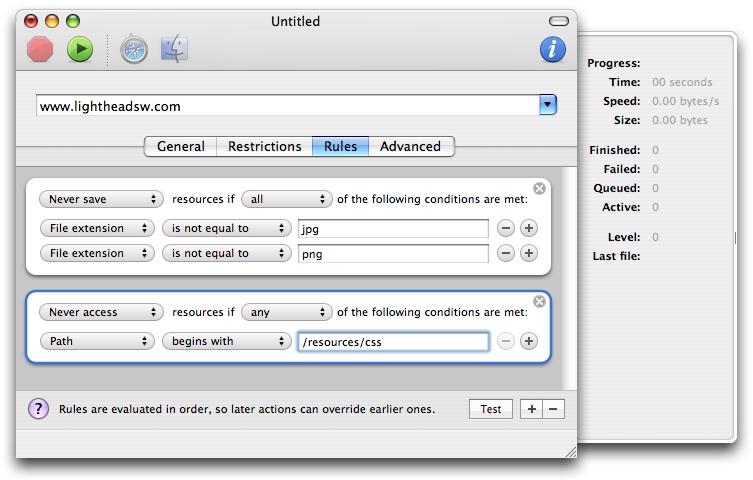
You can set up rules that SiteCrawler obeys when crawling a website. For example, you may want to exclude all files whose file extension is 'jpg'. Or, you may want to explicitly allow SiteCrawler to follow links to certain domains that are not normally included. You can arrange rules like these in the Rules list. The rules are evaluated in order, so later rules can override previous ones.
SiteCrawler 1.1 improves rules even further by adding a nice new user interface and the ability to assign several conditions to a rule. It's now possible to test rules out beforehand.
 Unlike any other site downloader, SiteCrawler can automatically use session cookies from Safari. Often, web sites protect resources with passwords, and it's normally very difficult to crawl protected areas of sites which use cookies for authentication. All you need to do to crawl the password-protected areas with SiteCrawler is to log in to them using Safari - SiteCrawler will figure out the rest.
Unlike any other site downloader, SiteCrawler can automatically use session cookies from Safari. Often, web sites protect resources with passwords, and it's normally very difficult to crawl protected areas of sites which use cookies for authentication. All you need to do to crawl the password-protected areas with SiteCrawler is to log in to them using Safari - SiteCrawler will figure out the rest.
SiteCrawler offers the option to install shortcuts in Safari. An item is inserted in the File menu to pre-fill a SiteCrawler session with the address of the current page. There is also a new entry in context menus, so you can start crawling a link.
* If you would like to help us translate SiteCrawler to your language, drop us a line!
Mac and the Mac logo are trademarks of Apple Computer, Inc., registered in the U.S. and other countries.